1. 前言
go语言现在这么出名的原因,主要是go语言设计简单、还有go语言的并行程序设计,在语言层面上就支持了并行。
2. 并发基础
在学习并发时,先了解下下面内容
2.1. 并发与并行
并发:把任务在不同的时间点交给处理器进行处理。在同一时间点,任务并不会同时运行。

并行:把每一个任务分配给每一个处理器独立完成。在同一时间点,任务一定是同时运行。
举个例子:
你正在吃苹果,客人来了在敲门,你直到吃完苹果再去开门,说明你不支持并发也不支持并行;
你正在吃苹果,客人来了在敲门,你停了下来去开门,开完门后继续吃苹果,说明你支持并发;
你正在吃苹果,客人来了在敲门,你一边吃苹果一边开门,说明你支持并行;
2.2. 进程、线程、协程
进程是资源分配的最小单位。同一时刻执行的进程数不会超过核心数。单核CPU也可以运行运行多进程,不过不是同时进行的,而是极快地在进程间来回切换实现多进程。
线程是CPU调度的最小单位。 线程(Thread)被包含在进程之中,是进程中的实际运作单位。每个进程至少有一个线程,同个进程中多个线程之间可以并发执行。
协程是一种用户态的轻量级线程。协程(coroutine)拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候, 恢复先前保存的寄存器上下文和栈(进入上一次离开时所处逻辑流的位置),避免了上下文切换的额外耗费,兼顾了多线程的优点,简化了高并发程序的复杂。
3. goroutine
goroutine是建立在线程之上的轻量级的抽象,是一个函数或方法,可以独立执行,也可以与程序中的其他Goroutine同时执行。 在Go语言中,当一个函数被创建为goroutine时,Go会将其视为一个独立最基本的执行单元,并且支持并发执行多个goroutine。
Go 协程(goroutine)和线程(Thread)
goroutine不同于线程,线程是操作系统的一部分,是依赖于硬件的。而goroutine是由go运行时管理的,不依赖于硬件,有简单的交流媒介,称为通道,由于通道的存在,一个goroutine可以与其他goroutine进行低延迟的通信。
线程没有方便的交流媒介,所以线程间的通信存在高延迟,启动也比Goroutines慢。另外每个 goroutine 默认占用内存远比线程少(goroutine:2KB ,线程:8MB)
Go 协程(goroutine)和协程(coroutine)
Goroutine和其他语言的协程(coroutine)在使用方式上类似,但是协程是一种协作任务控制机制,不是并发的,而Goroutine支持并发,因此Goroutine可以理解为一种Go语言的协程。同时它可以运行在一个或多个线程上。
3.1. goroutine的使用
goroutine 语法格式:
go function_name( parameter_list )
例子:
package main
import (
"fmt"
"time"
)
func eat(s string) {
for i := 0; i < 3; i++ {
time.Sleep(time.Second)
fmt.Println(s)
}
}
func main() {
go eat("青梅")
eat("李子")
}
输出的顺序是不确定:
李子
青梅
李子
青梅
青梅
李子
3.2. goroutine的局限性
在程序启动初始化 main package 并执行 main() 函数开始,Go程序就会为main()函数创建一个默认的goroutine,当 main() 函数返回时,程序退出,主goroutine就结束了, 程序并不等待其他goroutine(非主goroutine)结束。也就是主协程退出了,其它协程任务是不执行的。
package main
import (
"fmt"
"time"
)
func eat(s string) {
for i := 0; i < 3; i++ {
time.Sleep(time.Second)
fmt.Println(s)
}
}
func main() {
go eat("青梅")
fmt.Println("水果")
}
输出:
水果
需要主程序等一等eat函数,可以直接使用time.Sleep
package main
import (
"fmt"
"time"
)
func eat(s string) {
for i := 0; i < 3; i++ {
fmt.Println(s)
}
}
func main() {
go eat("青梅")
fmt.Println("水果")
time.Sleep(time.Second) // 等待一秒
}
可以看出是先打印水果后打印青梅,这是因为我们创建新的goroutine需要花费一些时间,此时main函数所在的主goroutine还是继续执行的。 输出:
水果
青梅
青梅
青梅
采用time.Sleep也不是万全之策,要是有一种机制可以使得goroutine和main()进行通信,让主函数等待所有goroutine退出后再返回,岂不是更好。 这就引出了多个goroutine之间通信的问题,如何知道goroutine都退出的消息通信机制,且看下面。
4. channel
通道(channel)是Go语言在语言级别提供的goroutine间的通信方式,可以使用channel在两个或多个goroutine之间传递消息。go语言中通道是一种特殊的类型,类似于队列,遵循先入先出的规则, channel是类型相关的,一个channel只能传递一种类型的值,这个类型需要在声明channel时指定。
4.1. channel声明和初始化
channel是一种引用类型。声明通道类型的格式如下:
var variable_name chan type
如:
var ch chan string // 声明一个传递字符串的通道
// 通道类型的空值是nil。
fmt.Println(ch) // 输出:<nil>
声明的通道后需要使用make函数初始化之后才能使用。
创建channel的格式如下:
make(chan type, [size])
channel的缓冲大小size是可选的。
如:
ch := make(chan int)
4.2. channel操作
通道channel有三种操作:发送(send)、接收(receive)和关闭(close)。
传数据用channel <- data,取数据用<-channel。
// 初始化一个通道
ch := make(chan int)
// 发送
ch <- 10 // 把10发送到ch中
// 接收
x := <- ch // 从ch中接收值并赋值给变量x(<- ch,也可直接接收值,忽略结果)
// 关闭通道
close(ch)
在通信过程中,传数据channel <- data和取数据<-channel是成对出现,而且不管传还是取,必阻塞,直到另外的goroutine传或者取为止。
另外关闭通道close()只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道,并且通道是可以被垃圾回收机制回收的。
例子:
package main
import "fmt"
func main() {
ch := make(chan string)
go func() { ch <- "青梅" }()
msg := <-ch
fmt.Println(msg) // 输出:青梅
}
4.3. 无缓冲的通道
go语言中无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道,只有在发送方goroutine和接收方goroutine都准备就绪时通信才能完成发送和接收操作。
下图展示两个 goroutine 如何利用无缓冲的通道来共享一个值。
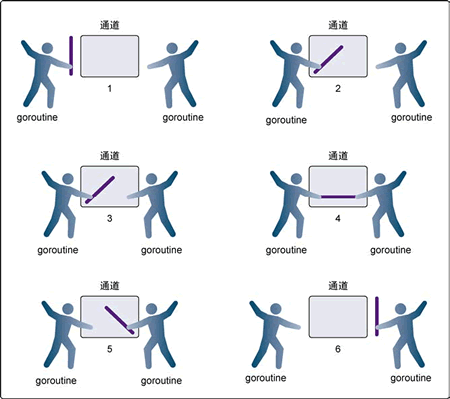
在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收。
在第 2 步,左侧的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在通道中被锁住,直到交换完成。
在第 3 步,右侧的 goroutine 将它的手放入通道,这模拟了从通道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成。
在第 4 步和第 5 步,进行交换,并最终在第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。两个 goroutine 现在都可以去做别的事情了。
初始化一个无缓冲通道时,不需要指定通道的容量,如:
ch := make(chan int)
例子:
package main
import (
"fmt"
)
func rece(c chan string) {
ret := <-c
fmt.Println("接收成功,接收值为:", ret)
}
func main() {
ch := make(chan string)
go rece(ch) // 启用goroutine从通道接收值
ch <- "雨中笑"
fmt.Println("发送成功")
}
输出:
接收成功,接收值为: 雨中笑
发送成功
4.4. 有缓冲的通道
go语言中有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。
这种类型的通道不会强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也会不同。 只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
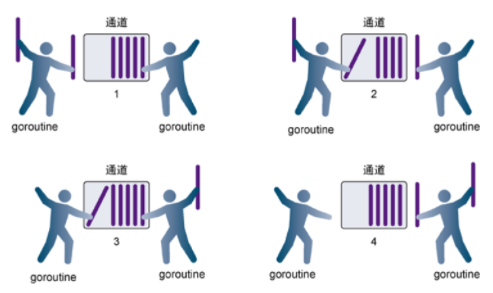
在第一步,左侧的goroutine不断的往通道中塞数据
在第二步,右侧的goroutine不断的从通道中拿数据
在第三步,一个读/一个写,同步作业
在第四步,左边的goroutine全部数据已经放完了,但此时通道中还剩余数据,所以右边的goroutine还在工作
初始化一个有缓冲通道时,需要指定通道的容量,如:
package main
import "fmt"
func main() {
// 创建一个2个元素缓冲大小的整型通道
ch := make(chan int, 2)
// 查看当前通道的大小
fmt.Println(len(ch))
// 发送2个整型元素到通道
ch <- 1
ch <- 2
// 查看当前通道的大小
fmt.Println(len(ch))
}
输出:
0
2
4.5. 通道关闭
当管道不往里存值或者取值的时候要关闭管道,可以通过内置的close()函数关闭channel
判断一个 channel 是否已经被关闭?我们可以在读取的时候使用多重返回值的方式:
x, ok := <-ch
如果ok是 false 则表示 ch 已经被关闭。
示例:
package main
import "fmt"
func main() {
c := make(chan int)
go func() {
for i := 0; i < 3; i++ {
c <- i
}
close(c)
}()
for {
if data, ok := <-c; ok {
fmt.Println(data)
} else {
break
}
}
fmt.Println("结束")
}
输出:
0
1
2
结束
4.6. 通道循环取值
package main
import "fmt"
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
// 开启goroutine将0~5的数发送到ch1中
go func() {
for i := 0; i < 5; i++ {
ch1 <- i
}
close(ch1)
}()
// 开启goroutine从ch1中接收值,并将该值乘2发送到ch2中
go func() {
for {
i, ok := <-ch1 // 通道关闭后再取值ok=false
if !ok {
break
}
ch2 <- 2 * i
}
close(ch2)
}()
// 在主goroutine中从ch2中接收值打印
for i := range ch2 { // 通道关闭后会退出for range循环
fmt.Println(i)
}
}
输出:
0
2
4
6
8
4.7. 单向通道
单方向的 channel 类型,就是只能用于写入或者只能用于读取数据
单向 channel 变量的声明,只写入数据的通道类型为chan<-,只读取数据的通道类型为<-chan,格式如下:
var only_send chan<- type // 只可发送;
var only_recv <-chan type // 只可接收
// 初始化
ch1 := make(chan<- int)
ch2 := make(<-chan int)
示例:
ch := make(chan int)
// 声明一个只能写入数据的通道类型, 并赋值为ch
var chOnlySend chan<- int = ch
//声明一个只能读取数据的通道类型, 并赋值为ch
var chOnlyRecv <-chan int = ch
只接收的通道(<-chan type)是无法关闭的,因为关闭通道是发送者用来表示不再给通道发送值。双向通道可转换成单向通道,如上述通道循环取值,可改造如下:
package main
import "fmt"
// 通道发送
func send(chOut chan<- int) {
for i := 0; i < 5; i++ {
chOut <- i
}
close(chOut)
}
// 接收通道并值乘2
func multiply(chOut chan<- int, chIn <-chan int) {
for i := range chIn {
chOut <- 2 * i
}
close(chOut)
}
// 循环输出通道
func printer(in <-chan int) {
for i := range in {
fmt.Println(i)
}
}
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go send(ch1)
go multiply(ch2, ch1)
printer(ch2)
}
4.8. 通道阻塞场景
阻塞场景共4个,有缓存通道和无缓通道冲各2个。
无缓冲通道的特点是,发送的数据需要被读取后,发送才会完成,它阻塞场景:
a、通道中无数据,但执行读通道。
b、通道中无数据,向通道写数据,但无协程读取。
有缓存通道的特点是,有缓存时可以向通道中写入数据后直接返回,缓存中有数据时可以从通道中读到数据直接返回,这时有缓存通道是不会阻塞的,它阻塞场景是:
c、通道的缓存无数据,但执行读通道。
d、通道的缓存已经占满,向通道写数据,但无协程读。
5. select
在不同的并发执行的协程中可以是使用关键字 select 来实现协程的切换,每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。具体格式如下:
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
select特点
每次执行select,都会只执行其中1个case或者执行default语句。
case后面跟的必须是读或者写通道的操作,否则编译出错。
当没有case或者default可以执行时,select则阻塞,等待直到有1个case可以执行。
当有多个case可以执行时,则随机选择1个case执行。
select可同时监听多个channel
package main
import (
"fmt"
"time"
)
func go1(ch chan int) {
time.Sleep(time.Second * 1)
ch <- 1
}
func go2(ch chan int) {
ch <- 2
}
func main() {
// 初始化2个管道
ch1 := make(chan int)
ch2 := make(chan int)
// 跑2个子协程,写数据
go go1(ch1)
go go2(ch2)
// 用select监控
select {
case c1 := <-ch1:
fmt.Println("执行协程:", c1)
case c2 := <-ch2:
fmt.Println("执行协程:", c2)
}
}
// 输出:执行协程: 2
可看出go1延迟1S,执行那么会执行 case c2,如果go1h和go2同时执行,则随机选择一个执行。(选择哪一个 case 取决于哪一个通道收到了信息)
在任何一个 case 中执行 break 或者 return,select 就结束了。
下面例子可以让通道退出:
package main
import "fmt"
func fibonacci(c, quit chan int) {
x := 1
for {
select {
case c <- x:
x = 2 * x
case <-quit:
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 5; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
fibonacci(c, quit)
}
在 select 中使用发送操作有 default 可以确保发送不被阻塞,如果没有 case,select 就会一直阻塞。
可用于判断有缓存管道是否存满:
package main
import (
"fmt"
"time"
)
// 判断管道有没有存满
func main() {
// 创建管道
ch1 := make(chan string, 5)
// 子协程发送数据
go send(ch1)
// 取数据
for s := range ch1 {
fmt.Println("res:", s)
time.Sleep(time.Second)
}
}
func send(ch chan string) {
for {
select {
// 写数据
case ch <- "中国":
fmt.Println("case:中国")
default:
fmt.Println("default:超过通道容量了")
}
time.Sleep(time.Millisecond * 500)
}
}
6. 锁
在实际项目中,可能会出现多个goroutine同时操作一个资源,这种情况会发生数据竞争,可能会导致最后得结果不符合预期,这时候加锁,就能很好地保证共享资源数据。
6.1. 互斥锁
互斥锁是一种常用的控制共享资源访问的方法,在并发程序中能保证同时只有一个goroutine可以操作共享资源,在Go中,sync.Mutex 提供了互斥锁的实现。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var mutex sync.Mutex
count := 0
for r := 0; r < 5; r++ {
go func() {
mutex.Lock() // 加锁
defer mutex.Unlock() // 在方法运行完之后解锁
count += 1
}()
}
time.Sleep(time.Second)
fmt.Println("the count is : ", count)
}
6.2. 读写锁
读写锁是对读写操作进行加锁。需要注意的是多个读操作之间不存在互斥关系,这样提高了对共享资源的访问效率。Go中读写锁由 sync.RWMutex 提供。
调用了“写锁”后,不能有其他goroutine进行读或者写操作
调用了“写解锁”后,会唤醒所有因为要进行“读锁定(即:RLock())” 而被阻塞的 goroutine。
多个读之间不存在互斥关系
写操作之间都是互斥的,并且写操作与读操作之间也都是互斥的
读锁
var m *sync.RWMutex //定义m的类型为读写锁。
m.RLock() //读锁定
m.RUnlock() //读解锁
写锁
var m *sync.RWMutex //定义m的类型为读写锁。
m.Lock() //写操作锁定
m.Unlock() //写操作解锁
例子:
package main
import (
"sync"
"time"
)
var m *sync.RWMutex
func main() {
m = new(sync.RWMutex)
// 写的时候啥也不能干
go write(1)
go read(2)
go write(3)
time.Sleep(2*time.Second)
}
func read(i int) {
println(i,"read start")
m.RLock()
println(i,"reading")
time.Sleep(1*time.Second)
m.RUnlock()
println(i,"read over")
}
func write(i int) {
println(i,"write start")
m.Lock()
println(i,"writing")
time.Sleep(1*time.Second)
m.Unlock()
println(i,"write over")
}
输出:
1 write start
1 writing
2 read start
3 write start
1 write over
2 reading
6.3. wait group
WaitGroup在go语言中,用于线程同步,它能够一直等到所有的goroutine执行完成,并且阻塞主线程的执行,直到所有的goroutine执行完成。(阻塞主线程等goroutine执行完之后再放开)
// 定义:
wg := new(sync.WaitGroup) //定义一个WaitGroup,就是用来等待都
var wg sync.WaitGroup
// 添加几个协程:
wg.Add(3) // 有几个进程需要等待就写几个,写多或写少都会报错
// 运行某个协程:
go func() {
wg.Done() //该进程结束就发送结束标志。
}()
// 标记所有协程执行完毕
wg.Wait() //等待所有协程结束后在执行以下都代码。
例子:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
tasks := []func(){
func() { time.Sleep(time.Second * 2); fmt.Println("one") },
func() { fmt.Println("two") },
}
var wg sync.WaitGroup
wg.Add(len(tasks))
for _, task := range tasks {
task := task
go func() {
defer wg.Done()
task()
}()
}
wg.Wait() // 获取信号量,main协程被阻塞。
fmt.Println("end")
}
输出:
two
one
end